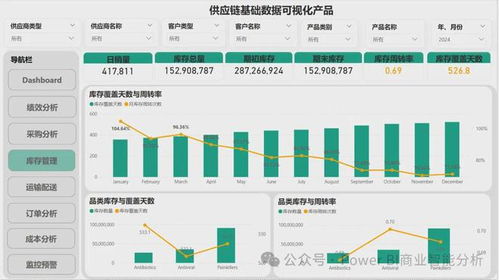
在当今数据驱动的商业环境中,供应链的透明化、智能化与高效化已成为企业提升竞争力的关键。借助微软Power BI这一强大的商业智能工具,企业能够构建端到端的供应链数据分析可视化产品,从而实现对供应链全流程的深度洞察与敏捷响应。本文将系统阐述如何基于Power BI构建供应链数据分析可视化解决方案,并重点介绍其背后至关重要的数据处理与存储支持服务体系。
一、 Power BI供应链数据分析可视化产品构建
一套完整的Power BI供应链可视化产品,旨在将分散、多源的供应链数据转化为直观、可交互的仪表板与报告,赋能决策者。其核心构建模块包括:
- 多维度分析视图:构建涵盖采购、生产、库存、物流、分销等核心环节的综合性仪表板。例如,通过地图可视化全球供应商分布与物流路径;使用时序图表监控库存水平波动与订单履行周期;通过矩阵和卡片图展示关键绩效指标(KPI),如订单准时交付率、库存周转率、供应商质量评分等。
- 预测与预警功能:集成Power BI的AI功能或与Azure机器学习服务连接,实现需求预测、库存预警(如安全库存预警)、物流延迟风险提示等。通过设置数据驱动的警报,系统可在指标异常时自动通知相关人员。
- 根源追溯与下钻分析:设计交互式报告,允许用户从高层级汇总数据(如区域销售总额)逐层下钻至具体细节(如特定仓库的SKU级别库存状态),快速定位问题根源。
- 移动端与协同共享:利用Power BI服务发布报告,支持在手机、平板等设备上安全访问,并可通过应用工作区实现团队内部或与关键合作伙伴的安全数据共享与协作。
二、 数据处理与存储支持服务:可视化产品的坚实基石
炫酷的可视化效果背后,是坚实、可靠的数据工程。数据处理与存储支持服务是确保整个分析系统准确、稳定、高效运行的核心。该服务体系通常涵盖以下层面:
- 数据源连接与集成:支持连接各类供应链数据源,包括ERP系统(如SAP、Oracle)、WMS(仓库管理系统)、TMS(运输管理系统)、供应商门户、IoT传感器数据以及Excel、CSV等文件。服务内容包括配置Power Query实现多源数据的无缝接入。
- 数据清洗与转换:在加载数据模型前,进行至关重要的ETL(抽取、转换、加载)过程。服务包括:去除重复项、处理缺失值、统一数据格式(如日期、货币)、拆分/合并列、建立规范的维表和事实表结构,以及实现复杂的业务逻辑计算(如计算在途库存、净需求)。
- 数据建模与优化:在Power BI Desktop中构建高效的数据模型。服务内容包括:建立正确的表关系(星型或雪花型架构)、创建计算列和关键度量值(使用DAX语言)、优化模型性能(如选择适当的聚合方式、管理关系方向)。一个优秀的数据模型是快速查询和准确计算的保障。
- 数据存储策略:根据数据量、刷新频率和成本考量,提供灵活的存储方案:
- Import模式:将数据导入Power BI高效的内置Vertipaq引擎中,适用于大多数数据集,提供极快的查询速度。
- DirectQuery模式:直接查询大型关系型数据仓库(如Azure SQL Database, Synapse Analytics),数据保留在源端,适用于超大规模或近实时数据场景。
- 复合模式:结合上述两者,对部分大表使用DirectQuery,对核心维度表使用Import,实现性能与灵活性的平衡。
- 数据刷新与管道自动化:配置并自动化数据刷新计划,确保可视化产品中的信息时效性。服务包括设置网关以连接本地数据源、在Power BI服务或Azure Data Factory中编排数据刷新流水线,并监控刷新状态与性能。
- 安全与治理:实施行级安全(RLS),确保不同部门(如采购、物流)的用户仅能查看其权限范围内的数据。建立数据字典、维护文档,确保整个数据资产的可管理性与可维护性。
三、 实施价值与展望
通过将Power BI前端可视化能力与专业的数据处理存储后端服务相结合,企业能够:
- 提升决策速度与质量:实时洞察供应链状态,从被动响应转向主动管理。
- 优化运营成本:精准识别库存冗余、物流瓶颈或供应商风险,助力降本增效。
- 增强供应链韧性:通过模拟分析与预警,提高应对突发 disruptions 的能力。
随着与Azure云服务(如Azure Data Lake, Databricks)的更深度集成,供应链数据分析平台将能处理更海量、更多样化的数据,并融入更高级的预测性与规范性分析,最终推动供应链向全面自治与智能化的方向演进。