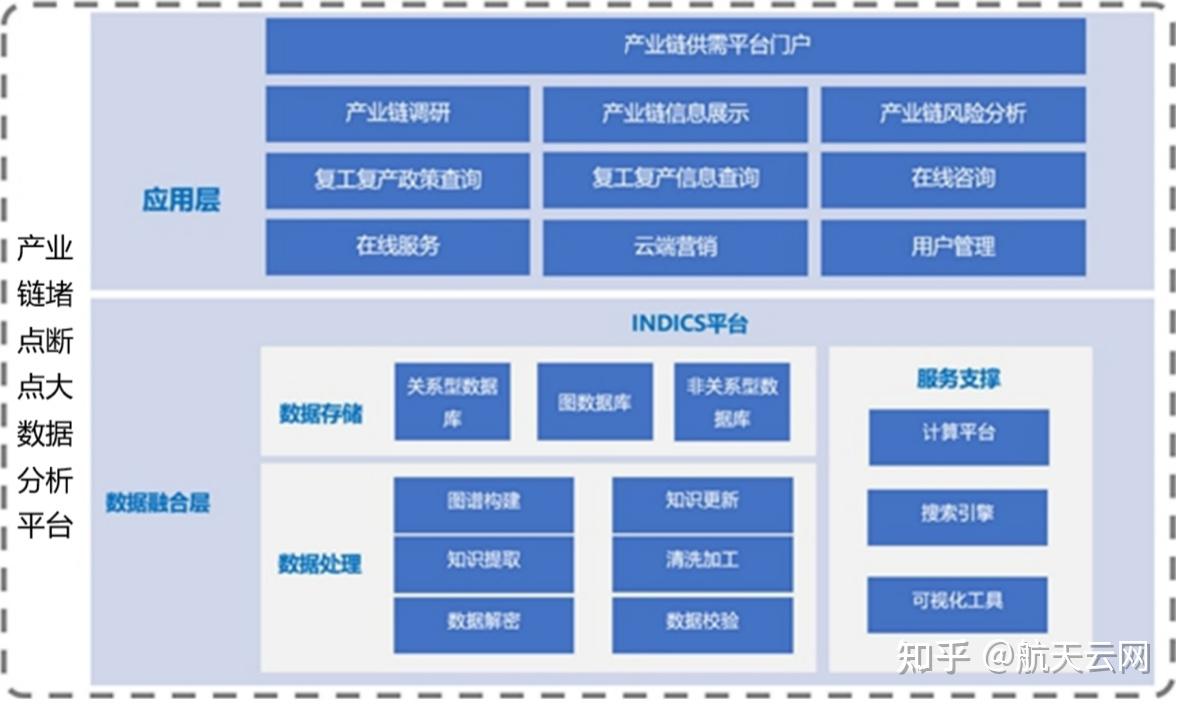
在当今全球化和数字化的经济背景下,产业链的高效、稳定运行至关重要。产业链中存在的堵点和断点问题,如供应链中断、信息不对称、产能瓶颈等,严重制约了整体效能与韧性。为精准识别、预测并疏通这些关键节点,大数据分析技术成为核心工具。而这一切的基础,在于强大、可靠的数据处理与存储支持服务。本解决方案旨在构建一套专为产业链堵点断点分析而设计的数据基石。
一、 核心挑战与需求
产业链数据具有来源广、类型杂、体量大、时效性要求高的特点。来自生产、物流、销售、金融、政策等多维度的数据,包括结构化数据(如ERP、SCM系统数据)、半结构化数据(如XML/JSON格式的订单、报关单)和非结构化数据(如行业报告、新闻舆情、传感器日志、图像视频),构成了分析的原材料。如何高效地采集、清洗、整合并存储这些海量异构数据,是精准分析的首要挑战。
二、 数据处理支持服务:从原始数据到分析就绪
- 多源异构数据采集与接入:
- 服务内容:提供API接口、数据库直连、文件传输、网络爬虫(遵守合规与伦理)、物联网(IoT)设备接入等多种方式,无缝对接企业内部系统(ERP, CRM, MES)、外部平台(电商、物流追踪平台)、公开数据库及物联网传感器网络。
- 技术实现:采用分布式消息队列(如Kafka, Pulsar)作为数据总线,实现高吞吐、低延迟的实时数据流接入。
- 数据清洗与标准化:
- 服务内容:对原始数据进行去重、纠错、补全、格式转换。针对产业链关键实体(如企业、产品、地理位置)进行识别、消歧与统一编码,建立全链条一致的“数据身份证”。
- 技术实现:利用基于规则和机器学习的数据质量框架,结合领域知识图谱,自动化执行清洗任务,确保数据的一致性与可信度。
- 数据融合与关联:
- 服务内容:将来自不同源头、描述同一业务对象(如一个零部件从生产到装配的全过程)的数据进行关联与整合,构建跨越企业边界的产业链全景视图。
- 技术实现:通过实体解析、关系挖掘和图计算技术,构建动态的“产业链数字孪生”数据模型,清晰呈现上下游企业、产品、物流、资金流和信息流之间的复杂网络关系。
三、 数据存储支持服务:弹性、智能的存储底座
- 分层存储架构:
- 热数据层(实时分析):采用高性能的分布式内存数据库(如Redis)或时序数据库(如InfluxDB),存储近期的实时交易数据、传感器数据,支撑毫秒级响应的堵点预警(如某物流节点突然停滞)。
- 温数据层(交互式分析):利用分布式数据仓库(如ClickHouse, Greenplum)或大规模并行处理(MPP)数据库,存储清洗整合后的历史明细数据,支持复杂的即席查询和多维分析,用于定位断点根源。
- 冷数据层(长期归档与挖掘):将海量历史数据、文档、音视频资料存储于低成本、高可靠的对象存储(如Amazon S3, 阿里云OSS)或HDFS中,供长期的趋势分析、模型训练和合规审计使用。
- 数据湖与数据仓库结合:
- 建立企业级数据湖,作为原始数据的集中存储池,保留数据的原始形态,提供最大的灵活性。根据分析主题(如供应链风险、产能利用率),从数据湖中抽取、转换、加载(ETL/ELT)数据到专业的数据仓库或数据集市中,形成高性能、易用的分析模型。
- 弹性扩展与高可用保障:
- 存储服务基于云原生架构,可根据数据量的增长和应用负载的变化,实现计算与存储资源的秒级弹性伸缩。通过多副本、跨可用区部署等技术,确保数据持久性不低于99.999%,服务可用性不低于99.9%,为7x24小时不间断的产业链监控提供坚实保障。
四、 服务价值与产出
通过本数据处理与存储支持服务,客户将获得:
- 统一可信的数据资产:形成覆盖产业链全环节的、高质量、标准化的单一事实来源。
- 实时与批处理一体化的能力:既能对突发堵点进行秒级感知与响应,也能对深层次、周期性的断点问题进行深度挖掘。
- 灵活高效的分析基础:为上层的大数据分析应用(如风险预警模型、供应链优化仿真、韧性评估指数)提供稳定、高性能的数据供给。
- 成本优化:通过合理的数据分层与生命周期管理,在满足性能需求的有效控制总体存储与计算成本。
###
数据处理与存储支持服务是产业链堵点断点大数据分析解决方案的“地基”。只有构建起坚实、智能、弹性的数据基础设施,才能让数据真正流动起来,转化为洞察力与决策力,最终实现产业链的畅通无阻、韧性增强与价值提升。