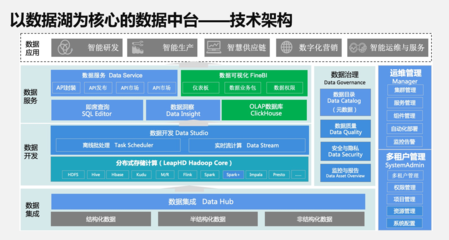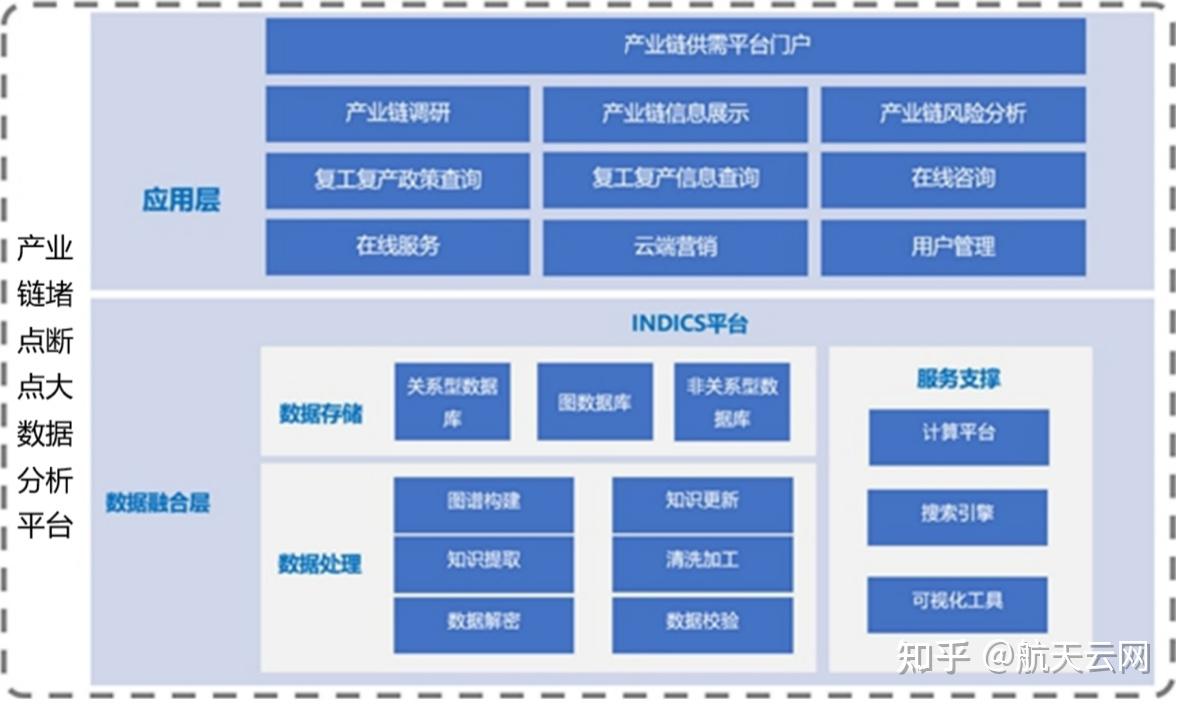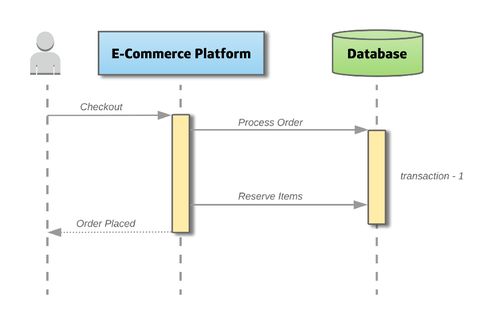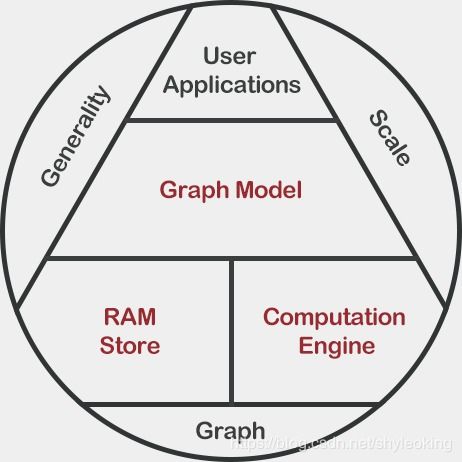
在当今数据爆炸的时代,图结构数据因其能直观表示实体间复杂关系,在社交网络分析、推荐系统、金融风控和知识图谱等领域得到广泛应用。为应对海量图数据带来的计算与存储挑战,Graphengine应运而生,其核心目标是打造一个高性能、可扩展的分布式图处理引擎,并构建完善的数据处理与存储支持服务体系,为用户提供一站式图计算解决方案。
核心目标一:分布式图处理引擎
Graphengine的首要设计目标是构建一个强大、灵活的分布式图处理引擎。传统单机图计算框架在处理十亿级乃至万亿级顶点和边的超大规模图时,常受限于内存、计算资源和网络带宽。Graphengine通过分布式架构,将图数据分区并存储于多台机器上,利用并行计算能力同时处理多个子图任务,显著提升了处理速度与规模上限。
该引擎支持多种图计算模型,包括以顶点为中心的编程模型(如Pregel)、以边为中心的模型以及基于矩阵运算的模型,兼容广度优先搜索(BFS)、最短路径(Shortest Path)、社区发现(Community Detection)和PageRank等经典图算法。引擎内置容错机制,确保在节点故障时任务能自动恢复,保障了长时间、大规模作业的稳定性与可靠性。
核心目标二:数据处理支持服务
图数据的价值不仅在于静态存储,更在于动态分析与实时处理。Graphengine提供全面的数据处理支持服务,涵盖数据摄取、清洗、转换和集成等环节。它支持从多种数据源(如关系数据库、NoSQL数据库、流数据平台及文件系统)导入数据,并转换为统一的图模型。通过内置的ETL工具,用户能定义复杂的数据转换规则,将原始数据映射为顶点、边及其属性,快速构建图数据集。
Graphengine强调对实时图处理的支持,能够对接流式数据源,持续更新图结构并触发增量计算。例如,在社交网络中实时捕捉用户互动,动态调整推荐策略;或在欺诈检测中即时分析交易链路,识别可疑模式。这种流批一体的处理能力,使得Graphengine既能应对历史数据的深度挖掘,也能满足实时场景的敏捷响应。
核心目标三:存储支持服务
高效的图存储是图计算性能的基石。Graphengine设计了一套分布式图存储系统,针对图数据的特性进行优化。它采用混合存储策略,将图结构(拓扑信息)与属性数据分离存储,前者常驻内存或高速存储以实现快速遍历,后者可持久化至分布式文件系统或对象存储,平衡性能与成本。
存储服务支持多种图数据模型,包括属性图、RDF图等,并提供丰富的查询接口,如Gremlin或Cypher查询语言,使用户能以声明式方式执行复杂图遍历。系统还具备数据压缩、索引自动构建和数据版本管理功能,提升存储效率与查询速度。通过横向扩展存储节点,Graphengine能线性增长存储容量与吞吐量,适应不断增长的数据规模。
整合与生态构建
Graphengine并非孤立系统,它致力于与现有大数据生态无缝集成。例如,可与Hadoop、Spark等计算框架协同,利用YARN或Kubernetes进行资源调度;也可将计算结果导出至数据仓库或可视化工具,形成从数据到洞察的闭环。通过提供标准API和SDK,Graphengine降低了开发门槛,使数据工程师和科学家能专注于业务逻辑,而非底层基础设施。
应用前景与挑战
随着图技术的普及,Graphengine的目标正逐步实现,在金融、电信、医疗和智能安防等领域展现出巨大潜力。分布式图处理仍面临挑战,如数据分区带来的通信开销、动态图的高效更新以及多租户环境下的资源隔离等。Graphengine需持续优化算法与架构,引入机器学习增强的图分析能力,并强化安全与隐私保护机制,以巩固其作为下一代数据基础设施的核心地位。
Graphengine以分布式图处理引擎为核心,辅以全面的数据处理与存储支持服务,旨在破解大规模图计算的瓶颈,赋能企业挖掘数据关联价值,驱动智能化决策与创新。